VPP Technology
The Technology Behind FD.io
At the heart of FD.io is Vector Packet Processing (VPP).
In development since 2002, VPP is production code currently running in shipping products. It runs in user space on multiple architectures including x86, ARM, and Power architectures on both x86 servers and embedded devices. The design of VPP is hardware, kernel, and deployment (bare metal, VM, container) agnostic. It runs completely in userspace.
VPP helps FD.io push extreme limits of performance and scale. Independent testing shows that, at scale, VPP-powered FD.io is two orders of magnitude faster than currently available technologies.
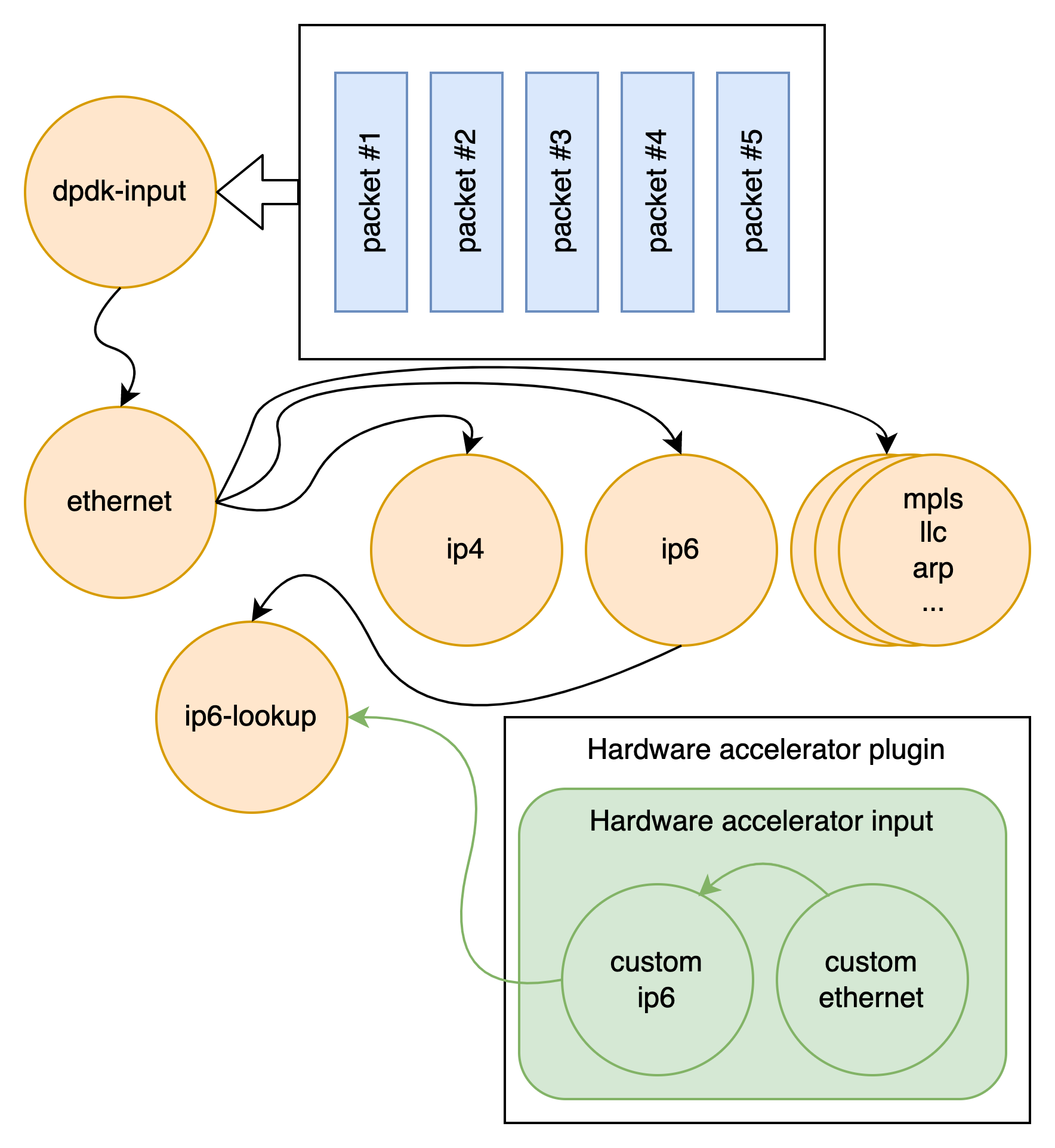
VPP reads the largest available vector of packets from the network IO layer.
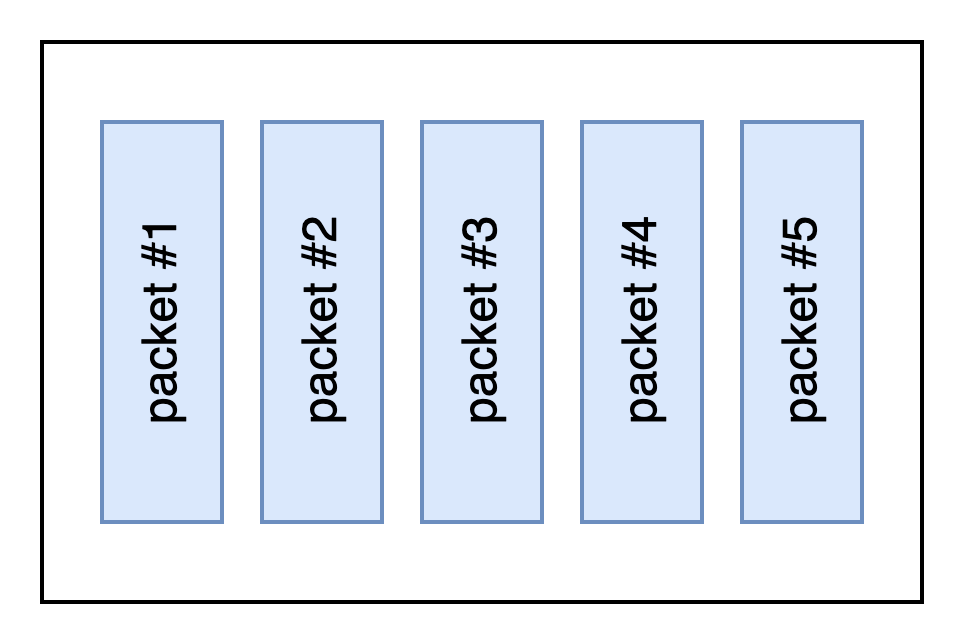
VPP then processes the vector of packets through a Packet Processing graph.
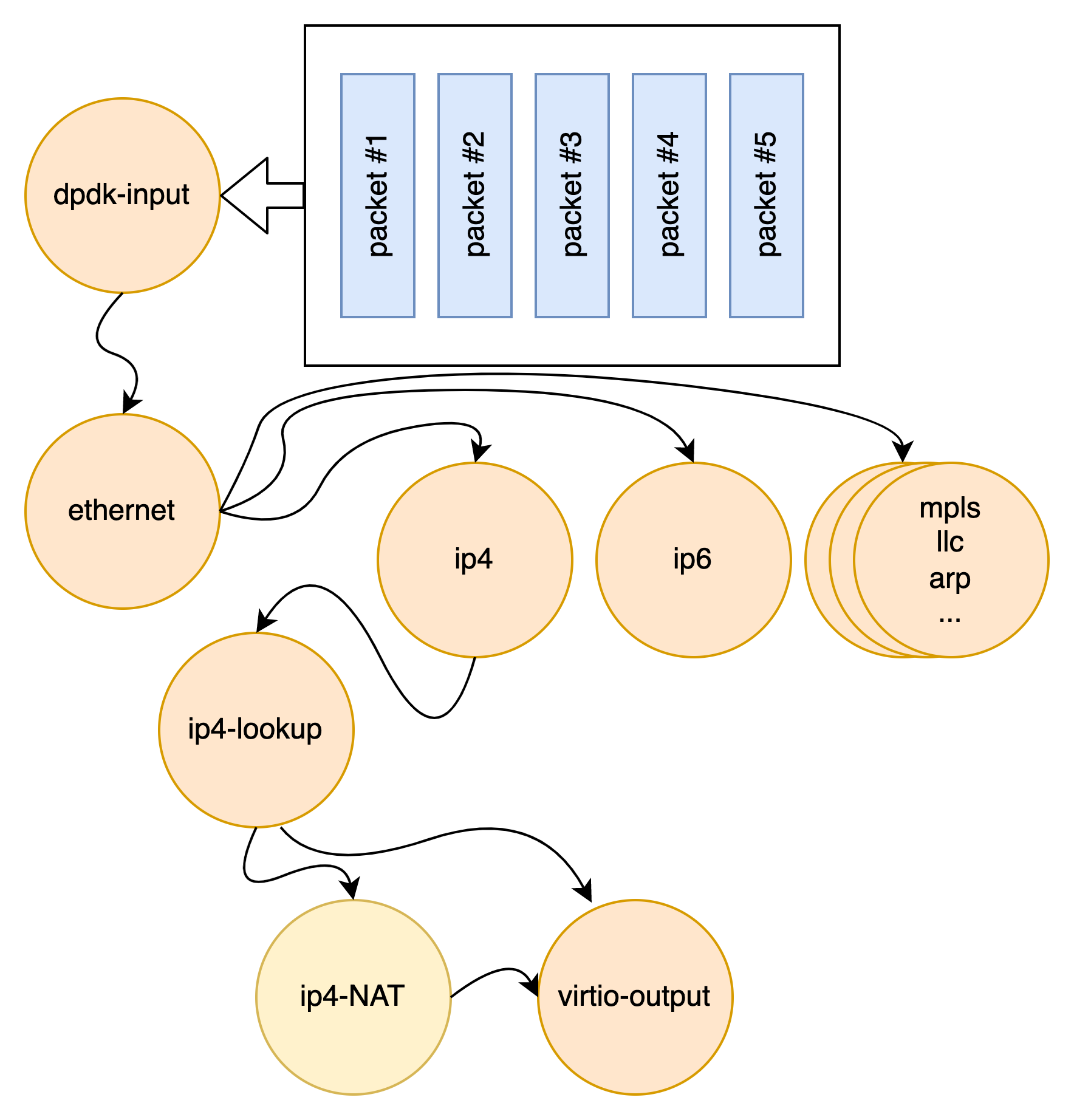
Rather than processing the first packet through the whole graph, and then the second packet through the whole graph, VPP instead processes the entire vector of packets through a graph node before moving on to the next graph node.
Because the first packet in the vector warms up the instruction cache, the remaining packets tend to be processed at extreme performance. The fixed costs of processing the vector of packets are amortized across the entire vector. This leads not only to very high performance, but also statistically reliable performance. If VPP falls a little behind, the next vector contains more packets, and thus the fixed costs are amortized over a larger number of packets, bringing down the average processing cost per packet, causing the system to catch up. As a result, throughput and latency are very stable. If multiple cores are available, the graph scheduler can schedule (vector, graph node) pairs to different cores.
A rough everyday analogy to this would be to consider the problem of a stack of lumber where each piece of lumber needs to be cut, sanded, and have holes drilled in it. You can only have one tool in your hand at a time (analogous to the instruction cache). You are going to finish cutting, sanding, and drilling the lumber faster if you first pick up the saw and do all of your cutting, then pick up the sander and do all of your sanding, and then pick up the drill and do all of your drilling. Picking up each tool in order for each piece of lumber is going to be much slower.
The graph node architecture of VPP also makes for easy extensibility. You can build an independent binary plugin for VPP from a separate source code base (you need only the headers). Plugins are loaded from the plugin directory. A plugin for VPP can rearrange the packet graph and introduce new graph nodes. This allows new features to be introduced via the plugin, without needing to change the core infrastructure code.
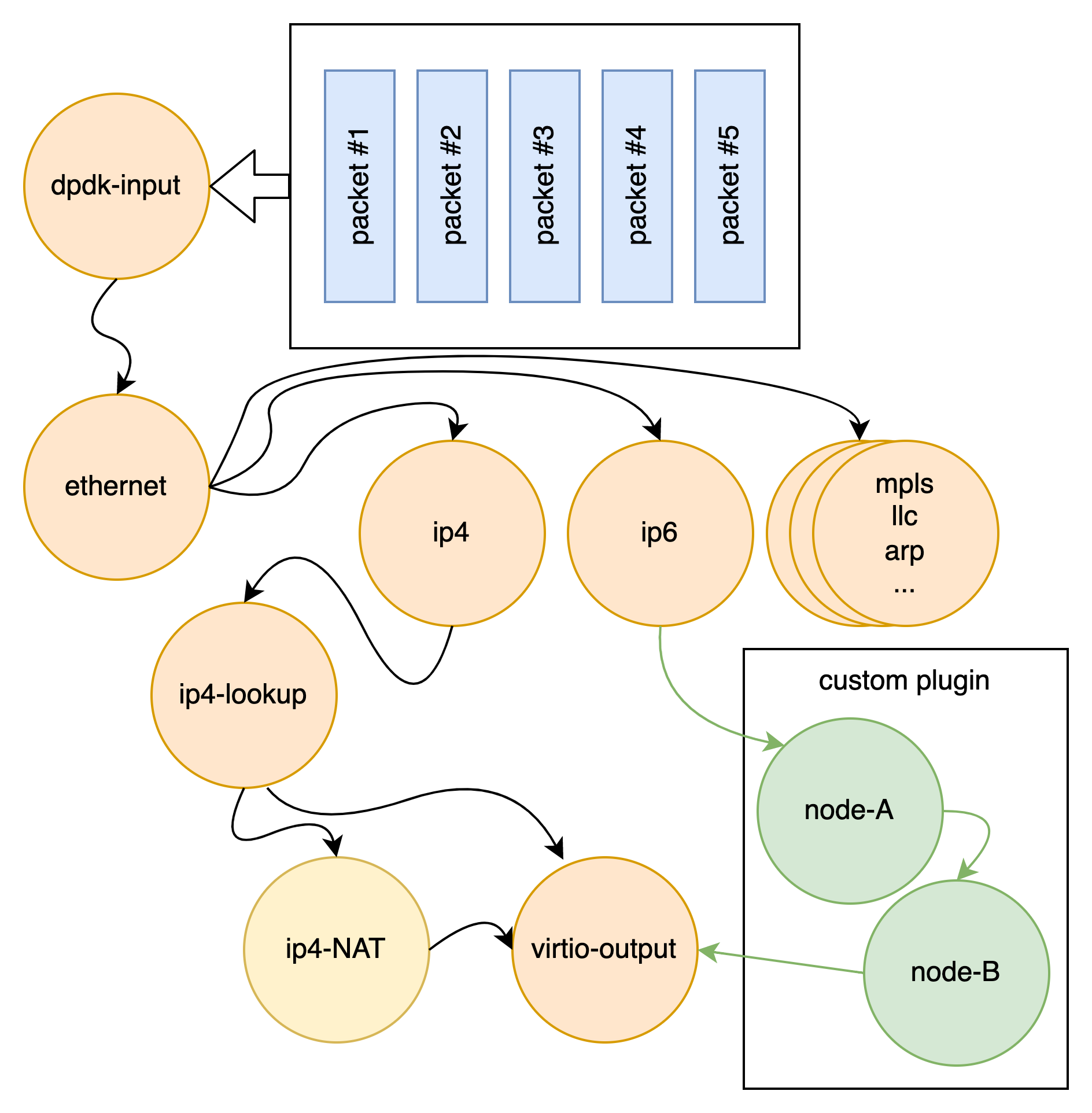
Hardware Acceleration
This same graph node architecture also allows FD.io to dynamically take advantage of hardware acceleration when available, allowing vendors to continue to innovate in hardware without breaking the “run anywhere” promise of FD.io’s software.
Logically, you can think of accelerating hardware as replacing some of the software graph nodes with hardware that performs the same function, only faster. Because a hardware accelerator vendor can enable this by simply providing a plugin that acts as an input node that hands off to the first graph node that is to perform a function in software, or by providing an output node which is handed off to as soon as the software processing is finished. In this way, accelerating hardware can be used if present, but functionality continues if it is missing or its resources are exhausted. This architecture allows maximum space for innovation by hardware accelerators.